The Hidden Looker Costs
Streamline your analytics spending

BigQuery and Looker are great products and work nicely together, however, it is a challenge to analyze and understand exactly how Looker usage generates cost to optimize it.
In BigQuery you can get the cost data and in Looker, you get usage data, but you can't get both joined together in one place
Using BigQuery we can gain some deeper knowledge about the costs using the INFORMATION_SCHEMA.JOBS view. This feature provides valuable data, such as total bytes processed, total bytes billed, referenced tables, and the query SQL text.
However, a critical piece of the puzzle remains elusive: a direct correlation between these costs and the reports and dashboards that initiate these queries.
The BigQuery INFORMATION_SCHEMA views are read-only, system-defined views that provide metadata information about your BigQuery objects.
– From https://cloud.google.com/bigquery/docs/information-schema-intro
Considering dashboards, it's important to note their potential to execute multiple queries. In practice, it's not uncommon to encounter dashboards that trigger over 50 query runs, each contributing to the overall cost.
In this article, I wanted to go through how me and my team at Mathem linked Looker usage data with GCP billing to give us a better overview of how much queries, dashboards, and looks cost.
I’ve included a chart of the whole workflow.

Looker - GCP Guide
If you haven’t already done it, first enable cloud billing export to BigQuery.
Create a new Looker user and grant the see_system_activity permission to have access to Looker's System Activity Explores.
Generate API credentials for the Looker user
To link Looker usage data with BigQuery cost data, we will use the history.slug field from History Explore in Looker and the label looker-context-history_slug from gcp_billing_export table in BigQuery
Starting with Looker data:
The fields we will export from Looker are:
history.created_raw
history.id
history.source
history.slug
history.result_source
history.status
history.connection_name
history.message
query.id
query.slug
query.model
query.view
dashboard.id
dashboard.title
look.id
look.slug
look.title
merge_query.id
sql_query.id
sql_query.slug
user.email

We will use Python to create the app for Looker data extraction.
I recommend doing this in a Python virtual environment (e.g virtualevn)
Ensure that you have your credentials in order
The Looker credentials can be stored in a .ini file or as local variables, we will use a .ini file.
Read more about it in sdk-codegen#securing-your-sdk-credentials
The Application
In Looker, once a query is created it's immutable and is not deleted. If you create a query that is exactly like an existing query then the existing query will be returned and no new query will be created.
Read more Looker API docs - create query
Lookers API offers multiple result formats, we will use “json”
Install the Looker SDK
pip install looker-sdkimport looker_sdk
from looker_sdk.sdk.api40 import models as models40
looker_client=looker_sdk.init40() # using API 4.0
query_body = models40.WriteQuery(
model="system__activity",
view="history",
fields=[
"history.created_raw",
"history.id",
"history.source",
"history.slug",
"history.result_source",
"history.status",
"history.connection_name",
"history.message",
"query.id",
"query.slug",
"query.model",
"query.view",
"dashboard.id",
"dashboard.title",
"look.id",
"look.slug",
"look.title",
"merge_query.id",
"sql_query.id",
"sql_query.slug",
"user.email",
],
)
looker_query = looker_client.create_query(body=query_body)
results = looker_client.run(query_id=looker_query.id, result_format="json")
The payload looks as follows (“flattened”):
[
{
"history.created_raw": "2023-11-26 00:00:23",
"history.id": 12345678,
"history.source": "dashboard",
"history.slug": "123abc123abc123bac",
"history.result_source": "query",
"history.status": "complete",
"history.connection_name": "connection_name",
"history.message": null,
"query.id": 123123,
...
},
...
]
Let’s create a convert the data to a Dict using our unflatten_dict function.
def unflatten_dict(
data: Dict[str, Any],
result: Dict[str, Any] = {},
) -> Dict[str, Any]:
"""
Convert any keys containing dotted paths to nested dicts
e.g {'a.b.c': 12}) -> {'a': {'b': {'c': 12}}}
"""
for key, value in data.items():
root = result
###
# If a dotted path is encountered, create nested dicts for all but
# the last level, then change root to that last level, and key to
# the final key in the path.
#
# This allows one final setitem at the bottom of the loop.
#
if "." in key:
*parts, key = key.split(".")
for part in parts:
root.setdefault(part, {})
root = root[part]
if isinstance(value, dict):
value = unflatten_dict(value, root.get(key, {}))
root[key] = value
return resultNow the data is ready to be published. Each item is published to a PubSub topic, from here a Dataflow job processes the PubSub message and writes it to BigQuery.
Read more about our Dataflow setup in this great post from Robert Sahlin:

In BigQuery
Once the data is in BigQeury, it gets deduplicated, and additional fields are added to make it easier to navigate to a specific Looker query, dashboard, or look.
We do this using dbt (data building tool)
Tip:
It’s possible to create links to dashboards and queries referenced in the looker data we just exported.
Query link = base_url_looker_instance/x/query_slug
Sql query link = base_url_looker_instance/x/sql_query_slug
Dashboard link = base_url_looker_instance/dashboards-next/dashboard_id
Look link = base_url_looker_instance/looks/look_id
Query page link = base_url_looker_instance/admin/queries/history_slug
Linking the Data
First, let’s create a query for the GCP billing information:
WITH
billing AS (
SELECT
billing_account_id,
service.id,
service.description,
labels_unnested,
cost,
currency
FROM
`project.dataset.gcp_billing_export_table,
UNNEST(labels) AS labels_unnested
)
SELECT
*
FROM
billing
WHERE
labels_unnested.key = "looker-context-history_slug"
AND labels_unnested.value = "123abc456def" # the Looker history slug
-- only records that generates cost
AND cost > 0
Next, joining the GCP billing with the Looker data, creating a view/table, let’s call it looker_cost
Note!
The usage/costs for all services are displayed with hourly granularity, which means long-running service usage is spread across multiple hourly windows.
We will therefore create a primary key/surrogate key from 'gcp_billing.export_time', 'gcp_billing.usage_start_time', and 'looker_history.id'
Read more Structure of Standard data export
# looker_cost.sql
WITH
gcp_billing AS (
SELECT
billing_account_id,
export_time,
usage_start_time,
label.value AS history_slug,
cost
FROM
` gcp_billing_export*` AS gcp_billing
CROSS JOIN UNNEST(labels) AS labels
WHERE
labels.key = 'looker-context-history_slug'
/**
* Some looker runs has two records in the gcp_billing table, one with cost 0 and one with cost > 0
* Only including records generating costs
*/
AND gcp_billing.cost > 0
)
SELECT
looker_history.* ,
gcp_billing.cost,
gcp_billing.history_slug,
{{ dbt_utils.generate_surrogate_key([
'gcp_billing.export_time',
'gcp_billing.usage_start_time',
'looker_history.id'
]) }} AS looker_cost_pk
FROM
gcp_billing
LEFT JOIN
looker_history_table AS looker_history
ON looker_history.slug = gcp_billing.history_slug
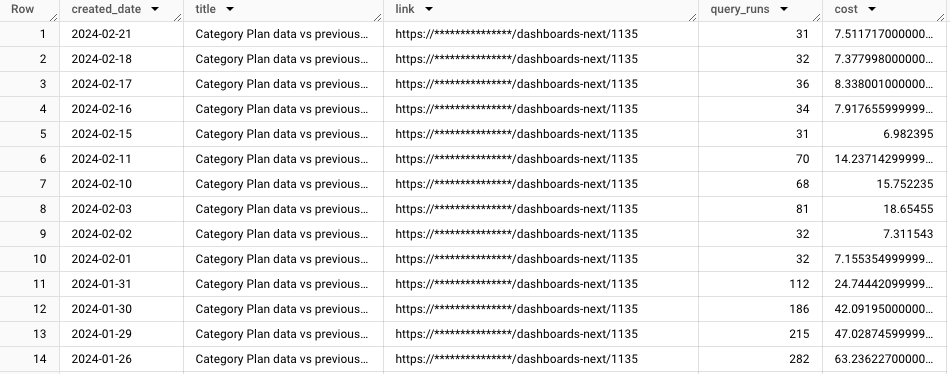
Lastly, create a query that is dashboard-focused, let's call it looker_dashboard_cost
# looker_dashboard_cost.sql
SELECT
DATE(created_raw, "your timezone") AS created_date,
dashboard.id,
dashboard.title,
dashboard.link,
ARRAY_AGG(
(SELECT AS STRUCT
query.model,
query.view AS explore,
query.link,
IF(query.id IS NULL , NULL, cost) as cost)
) AS queries,
ARRAY_AGG(
(SELECT AS STRUCT
sql_query.link,
IF(sql_query.id IS NULL , NULL, cost) as cost)
) AS sql_query,
ARRAY_AGG(
(SELECT AS STRUCT
merge_query.id,
IF(merge_query.id IS NULL , NULL, cost) as cost)
) AS merge_query,
ARRAY_AGG(user.email) AS users,
COUNT(dashboard.id) AS query_runs,
SUM(cost) AS cost
FROM
looker_cost
WHERE
dashboard.id IS NOT NULL
GROUP BY
created_date,
dashboard.id,
dashboard.title,
dashboard.link
Voila!